
Gitlab CI/CD
一、CI/CD概念
CI/CD 指的是软件开发的持续集成方法,我们可以持续构建、测试和部署软件。通过持续方法的迭代能使得我们减少在错误代码或者错误先前版本上的开发。从而也能提高开发的效率。
CI/CD 的持续集成方法主要分为三种:持续集成、持续交付、持续部署。下面我们分别介绍其在gitlab的概念。
持续集成:指的是开发人员每天多次推送代码的更改,对于每次推送到仓库,都可以创建一组脚本来构建和测试我们的应用程序。这些脚本将会减少我们在代码里引入错误的机会。
持续交付:指的是每次将代码推送到仓库,不仅会构建、测试我们的应用,并且会持续部署应用。但是对于持续交付,需要我们手动触发部署。
持续部署:是在持续交付的基础上更进一步,不同的是,持续交付需要我们手动部署,持续部署则是自动进行部署。
对于Gitlab CI/CD 其实与我们熟知的Jenkins、CircleCI概念上没有什么区别,其都是一套可以集成这些持续方法的系统。当然每套系统在集成过程中可能会略有不同、各有特色。
二、 Gitlab CI/CD 工作流
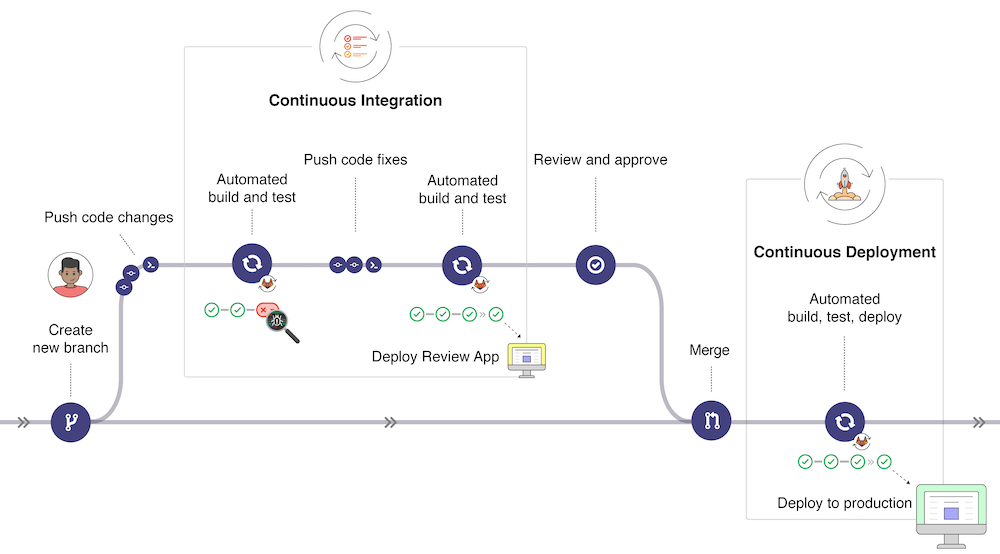
- 用户从主分支check一个分支,进行一些改动之后,push 改动到分支,这个时候会触发持续集成;
- 当持续集成进行自动构建、测试失败之后,需要用户再次提交fixed 代码,再次触发持续集成;
- 当持续集成通过之后进行review 以及 approve,然后merge 到主分支,触发持续交付/持续部署;
- 持续交付/持续部署进行自动构建、测试、部署,成功通过后应用即也成功部署了。
这就是gitlab CI/CD的工作流。
三、Runners
Runner 是gitlab CI/CD的重要组成概念。Runner顾名思义也就是执行器,它是gitlab 中执行job的机器。
Gitlab-host runners
gitlab.com 提供一系列Runner,其中包括以下四类:
- Hosted runners on Linux
- GPU-enabled hosted runners
- Hosted runners on Windows (Beta)
- Hosted runners on macOS (Beta)
其中基于windows和macOS的runner还处于beta版本,暂未开放使用。Linux 和 GPU是可以使用的,但是每个Runner都是有限制的,具体的限制是消耗系数(大概是),具体计算规则可以看cost factor,大概的意思就是可以使用免费的,但是计算数很少,可能不够用,所以就需要购买他们的订阅,如下价格:
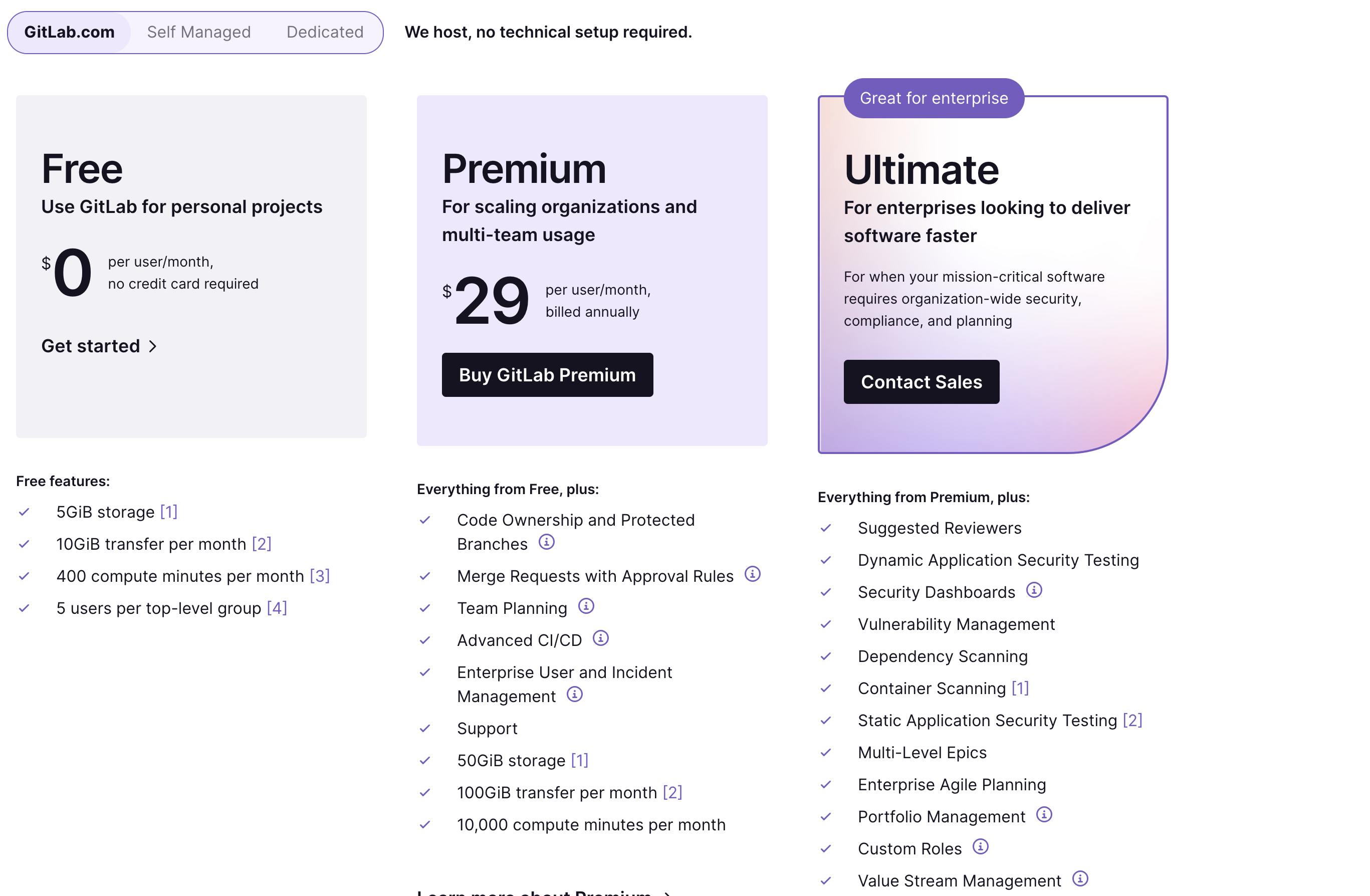
也就是说是需要money的。除了以上官方给我们提供的runner,我们还可以创建自己的runner。
个人的Runner
Runner根据你想要访问的人分为三类:共享runner、群组runner、项目runner
共享runner(shared runner):可用于gitlab实例中的所有群组项目;
群组runner (group runner): 可以用于群组中所有的项目和子组;
项目runner(project runner):与特定的项目关联,项目runner只用于一个项目。
安装gitlab runner
具体文档为:https://docs.gitlab.com/runner/install/
以macOS 为例:
# 1. curl 下载合适的gitlab-runner包
# 基于intel
sudo curl --output /usr/local/bin/gitlab-runner "https://s3.dualstack.us-east-1.amazonaws.com/gitlab-runner-downloads/latest/binaries/gitlab-runner-darwin-amd64"
# 基于Apple Silicon
sudo curl --output /usr/local/bin/gitlab-runner "https://s3.dualstack.us-east-1.amazonaws.com/gitlab-runner-downloads/latest/binaries/gitlab-runner-darwin-arm64"
# 2. 授予执行权
sudo chmod +x /usr/local/bin/gitlab-runner
# 3. 配置执行用户,启动gitlab-runner
su - <username>
cd ~
gitlab-runner install
gitlab-runner start
# 4.重启系统
config.toml 位于 /Users/<username>/.gitlab-runner/下, 此文件可进行更多的配置,文件内容如下:
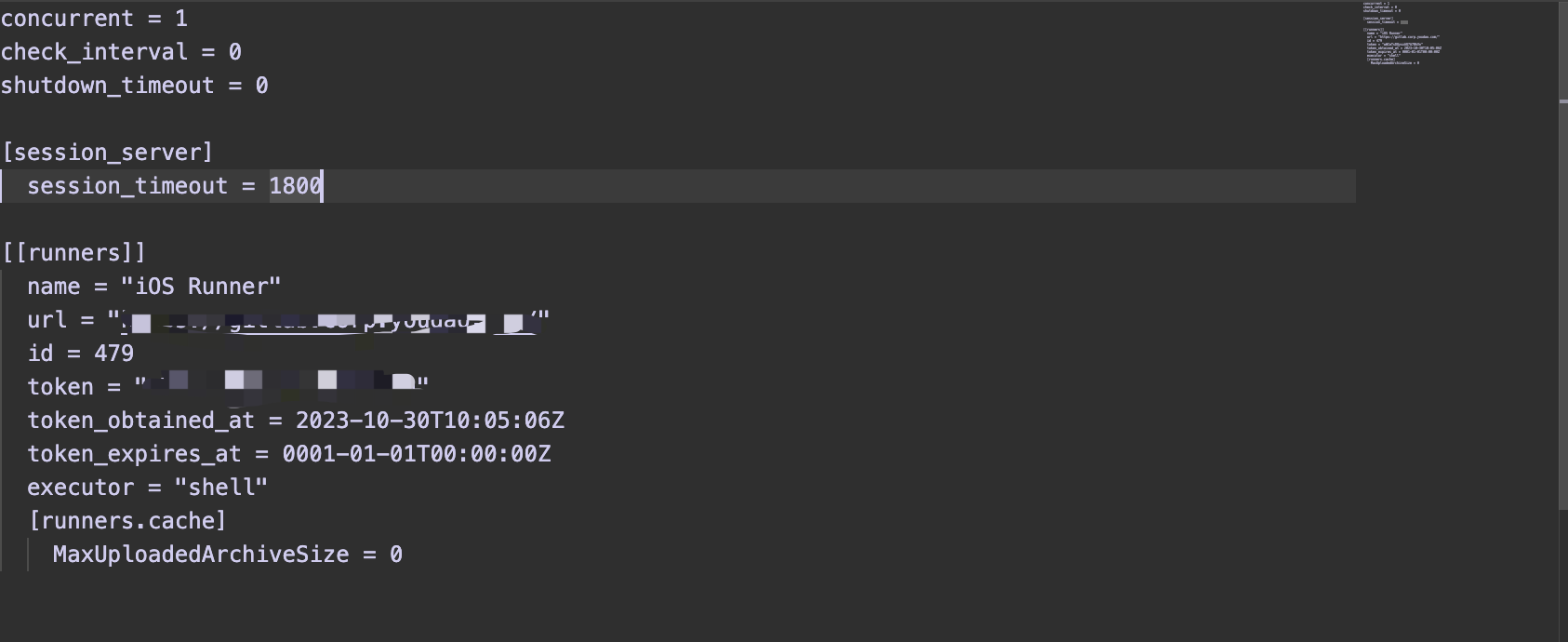
以上所有字段和可配置的字段都可以在文档里找到,具体文档为:https://docs.gitlab.com/runner/configuration/advanced-configuration.html
Runner 执行器
具体文档为:https://docs.gitlab.com/runner/executors/
我们先说Runner的执行器,之后在具体说Runner的相关配置。
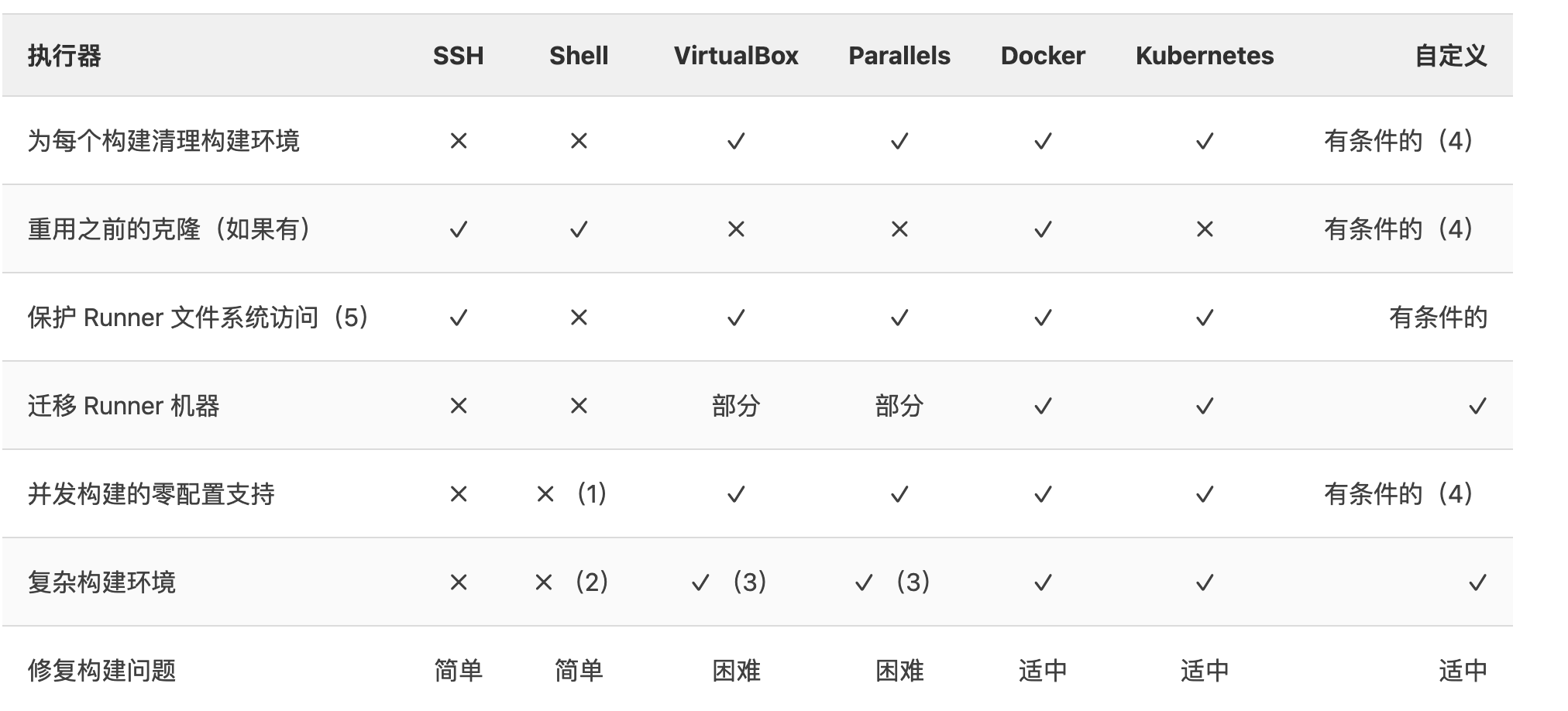
git 支持以上的执行器。选择执行器可按照以上对比选择。具体执行器介绍请查看:https://docs.gitlab.cn/runner/executors/#i-am-not-sure
Runner 配置
首先说一下三种Runner的配置:
配置shared runner 先决条件则是需要gitlab 管理员权限。
配置group runner 的先决条件则是需要group管理员权限。
配置project runner的先决条件则是拥有项目的管理权。
我们以project runner设置为例:
- 搜索或者去你的gitlab 项目
- 选择左边栏setting->CI/CD
- 展开Runners
- 找到你想要编辑的runner 点击左边Edit(铅笔)
- 设置Maximum job timeout job最大超时时间、以及一些其他的信息
当然我们也可以在job脚本里配置一些git相关的设置。详情查看https://docs.gitlab.com/ee/ci/runners/configure_runners.html#git-strategy
四、.gitlab-ci.yml 文件
定义 & 简单例子
.gitlab-ci.yml 文件是执行作业或者流水线的重要组成部分。说白了其实它就是一个配置文件,这个文件配置了job执行的过程、执行的脚本。
举个例子:
stages:
- build
- test
build-code-job:
stage: build
script:
- echo "Check the ruby version, then build some Ruby project files:"
- ruby -v
- rake
test-code-job1:
stage: test
script:
- echo "If the files are built successfully, test some files with one command:"
- rake test1
test-code-job2:
stage: test
script:
- echo "If the files are built successfully, test other files with a different command:"
- rake test2
这个例子中首先两个阶段,三个job组成,其中先执行build阶段job,再执行test阶段job,其中test有两个job,再test阶段这两个job并发执行。这样就组成了一个pipeline(流水线)。每次更改推到远程的时候流水线就会执行。当然我们可以查看执行过程就行终端执行一样,点击某个pipeline, 点击具体的stage job查看,如下:

.Gitlab-ci.yml关键字
配置流水线行为的全局关键字
| 关键字 | 描述 |
|---|---|
default |
作业关键字的自定义默认值。 |
stages |
流水线阶段的名称和顺序 |
workflow |
控制运行的流水线类型 |
include |
从其他 ymlL 文件导入配置。 |
作业关键字
| 关键字 | 描述 |
|---|---|
after_script |
覆盖作业后执行的一组命令 |
allow_failure |
允许作业失败。失败的作业不会导致流水线失败。 |
artifacts |
成功时附加到作业的文件和目录列表。 |
before_script |
覆盖在作业之前执行的一组命令 |
cache |
应在后续运行之间缓存的文件列表。 |
coverage |
给定作业的代码覆盖率设置。 |
environment |
作业部署到的环境的名称。 |
dast_configuration |
在作业级别使用来自 DAST 配置文件的配置。 |
dependencies |
通过提供要从中获取产物的作业列表,来限制将哪些产物传递给特定作业。 |
except |
控制何时不创建作业。 |
image |
使用 Docker 镜像。 |
extends |
此作业继承自的配置条目。 |
inherit |
选择所有作业继承的全局默认值。 |
interruptible |
定义当新运行使作业变得多余时,是否可以取消作业。 |
needs |
在 stage 顺序之前执行的作业。 |
only |
控制何时创建作业。 |
pages |
上传作业的结果,与 GitLab Pages 一起使用。 |
parallel |
应该并行运行多少个作业实例。 |
release |
指示运行器生成 release 对象。 |
resource_group |
限制作业并发。 |
retry |
在失败的情况下可以自动重试作业的时间和次数。 |
rules |
用于评估和确定作业的选定属性以及它是否已创建的条件列表。 |
script |
由 runner 执行的 Shell 脚本。 |
secrets |
作业所需的 CI/CD secret 信息。 |
services |
使用 Docker 服务镜像。 |
stage |
定义作业阶段。 |
tags |
用于选择 runner 的标签列表。 |
timeout |
定义优先于项目范围设置的自定义作业级别超时。 |
trigger |
定义下游流水线触发器。 |
variables |
在作业级别定义作业变量。 |
when |
何时运行作业。 |
具体的关键字使用可通过点击关键字进行超链接查看。
五、Variables (变量)
定义
CI/CD变量是一种环境变量,他们将用于控制作业、流水线;存储重复使用的值;避免在.gitlab-ci.yml 中硬编码。
预定义变量
每个Gitlab CI/CD中都有预定义变量方便使用,比如CI_JOB_NAME、GITLAB_USER_LOGIN、CI_COMMIT_BRANCH等
我们可以在ymll配置文件中直接使用,不需要声明,如下
job:
stage: test
script:
- echo "hello, '$GITLAB_USER_LOGIN'"
所有的预定义变量可以在:https://docs.gitlab.com/ee/ci/variables/predefined_variables.html 查看。
在.gitlab-ci.yml 中定义变量
在.gitlab-ci.yml 文件中定义变量,需要使用 variables 关键字定义变量和值。
如果变量定义在顶层则是全局变量,全局可用,如果定义到某个Job内则是局部变量,只有这个job可用。
如下:
variables:
GLOBAL_VAR: "A global variable"
job1:
variables:
JOB_VAR: "A job variable"
script:
- echo "Variables are '$GLOBAL_VAR' and '$JOB_VAR'"
job2:
script:
- echo "Variables are '$GLOBAL_VAR' and '$JOB_VAR'"
单个作业跳过全局变量
如果不想在作业中使用全局定义的变量,请将 variables 设置为 {}:
variables:
GLOBAL_VAR: "A global variable"
job1:
variables: {}
script:
- echo This job does not need any variables
在gitlab中增加CICD预定义变量
我们可以给项目、群组(group)、gitlab实例(私有化部署)增加全局变量。但是需要的权限也不一样:
项目先决条件:项目持有者
group先决条件:group管理员
gitlab实例先决条件:gitlab管理员
以项目为例:
-
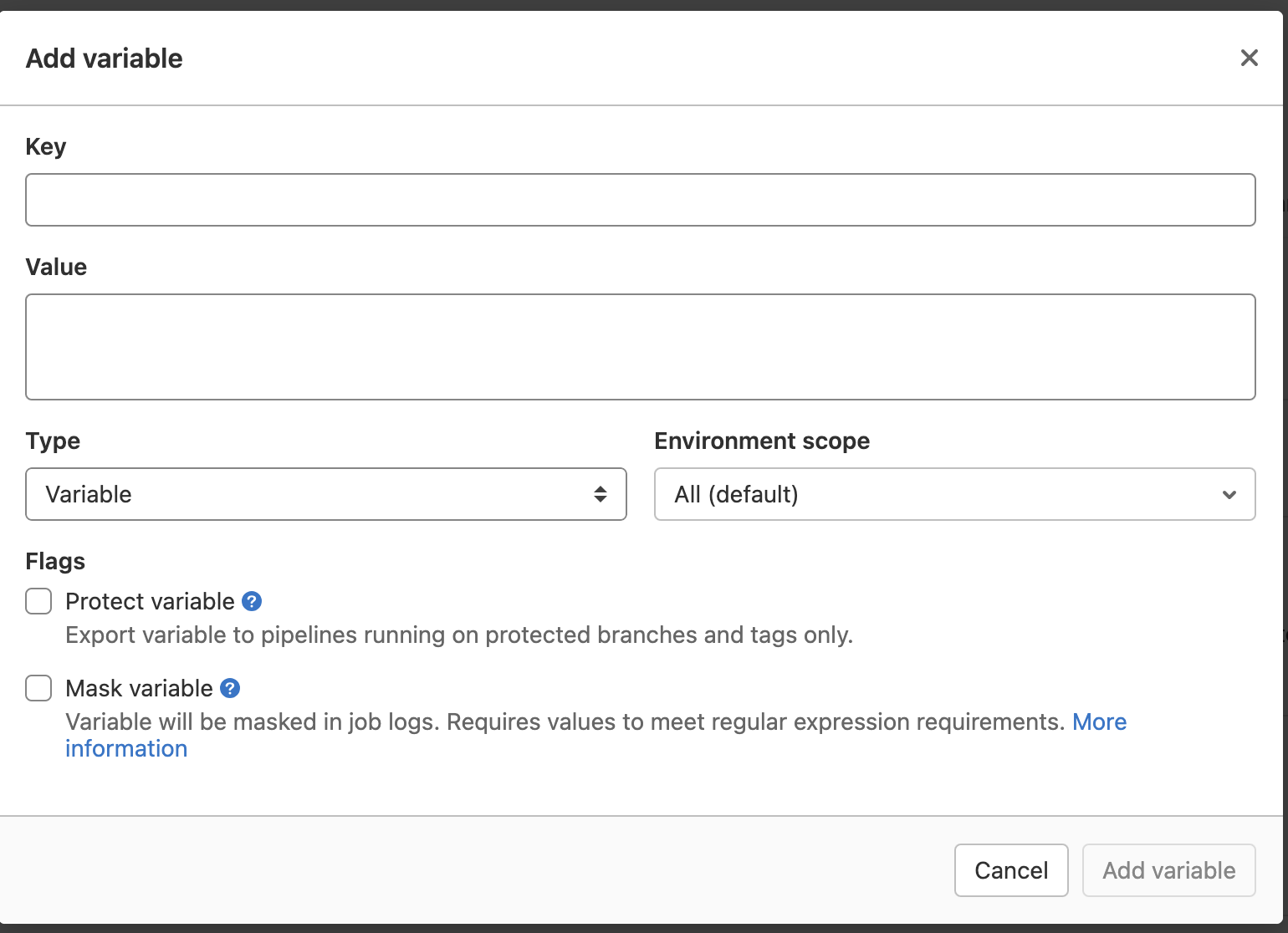
从项目左侧侧边栏CI/CD进入设置页面下的Variables 展开
-
添加变量并且填写详细信息,如下:
六、Pipeline(流水线)
定义
Pipeline是持续集成、交付、部署的顶级组件,如上内容中介绍的,它包括Stage(阶段)、job(作业)。job由Runner执行,同一个stage内的job将并发执行,在并发程序足够的情况下。如果Pipeline中一个Stage job都成功,pipeline将进入下一个阶段;如果某个失败,通常是不会进入到下个stage执行。
pipeline类型
- 基本流水线:同时运行每个阶段的所有内容,然后是下一个阶段。
- 有向无环图 (DAG) 流水线:基于作业之间的关系,可以比基本流水线运行得更快。
- 多项目流水线:将不同项目的流水线组合在一起。
- 父子流水线:将复杂的流水线分解为一个可以触发多个子流水线的父流水线,这些子流水线都运行在同一个项目中并具有相同的 SHA。这种流水线架构通常用于 mono-repos。
- 合并请求的流水线:仅针对合并请求运行(而不是针对每次提交)。
- 合并结果的流水线:是来自源分支的更改已经合并到目标分支的合并请求流水线。
- 合并队列:使用合并结果流水线将合并一个接一个地排队
配置pipeline
配置流水线是通过.gitlab-ci.yml文件进行配置,阶段使用stages关键字。

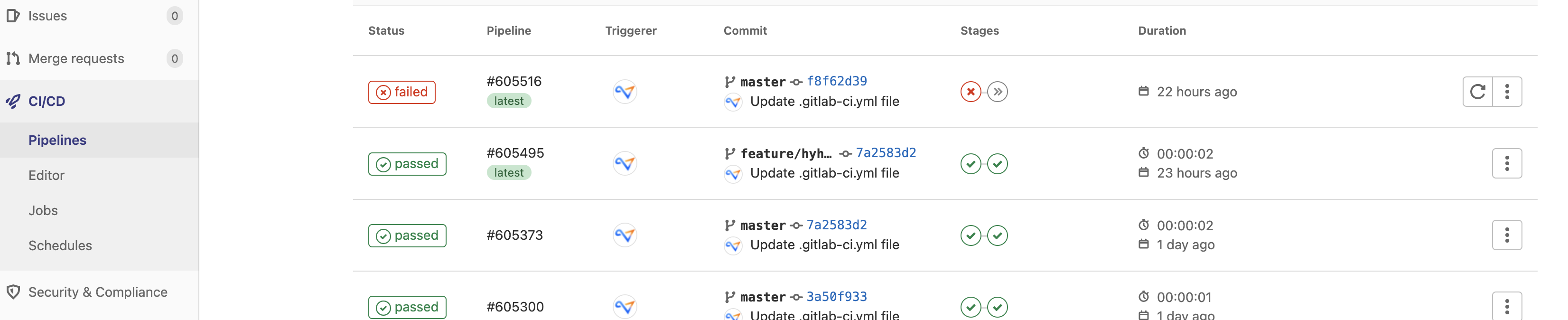
查看pipeline
选择项目左侧sidebar->CI/CD->Pipelines, 即可查看pipelines,如下:
七、Job(作业)
定义
我们所说流水线的配置是从配置作业开始的,作业是.gitlab-ci.yml配置文件里的最基本元素,它定义了约束条件,何种情况下执行,且包含script关键字的任意job名字,且可定义不限量的job。如下简单的两个job:

查看job
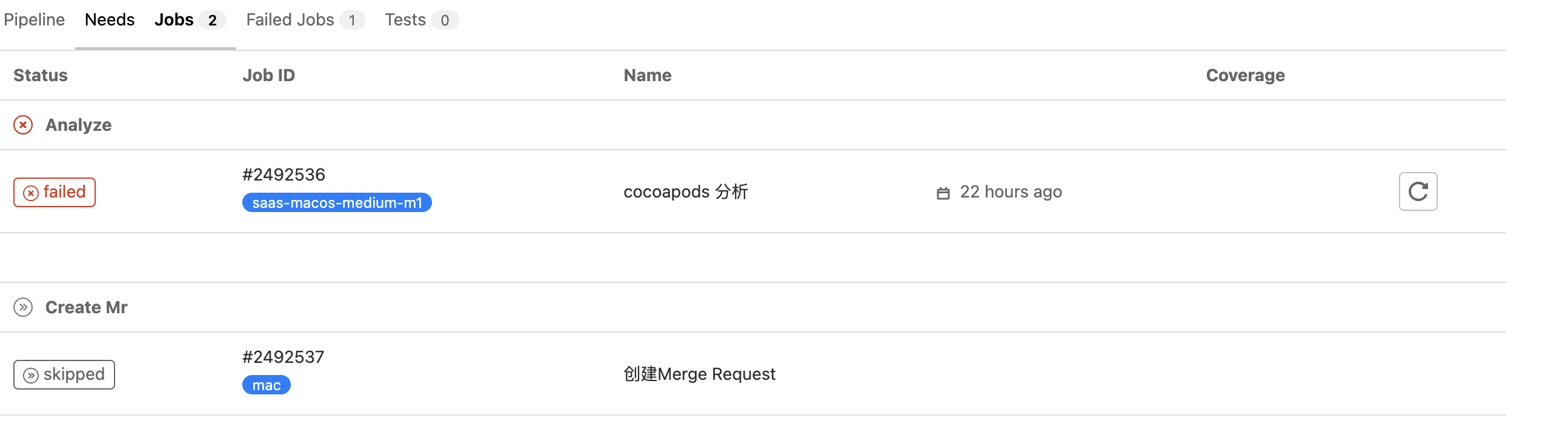
-
可从Pipeline里某个pipeline 点击进入查看具体的job,且可进行单个job的交互,如:失败后的重试、点击status直接进入日志等
-
从左侧边栏中的CI/CD->Jobs直接查看,同样可进行1中的交互

job 名字限制
不能使用gitlab-CI现有的关键词作为job名字,并且名字不能超过255个字符。
不能将这些关键字用作作业名称:
imageservicesstagestypesbefore_scriptafter_scriptvariablescacheincludetruefalsenil
分组作业
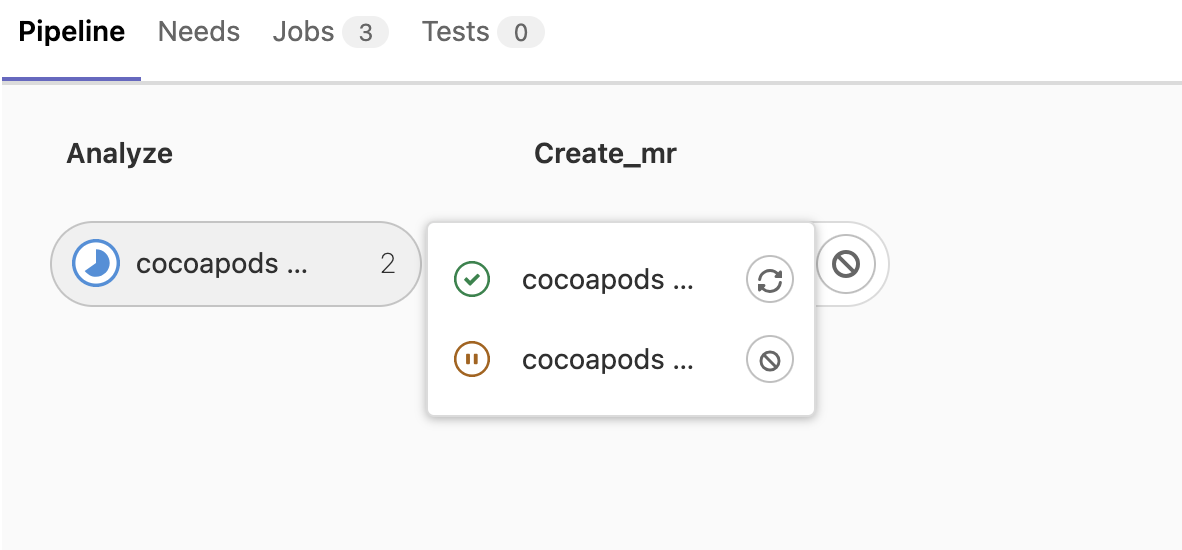
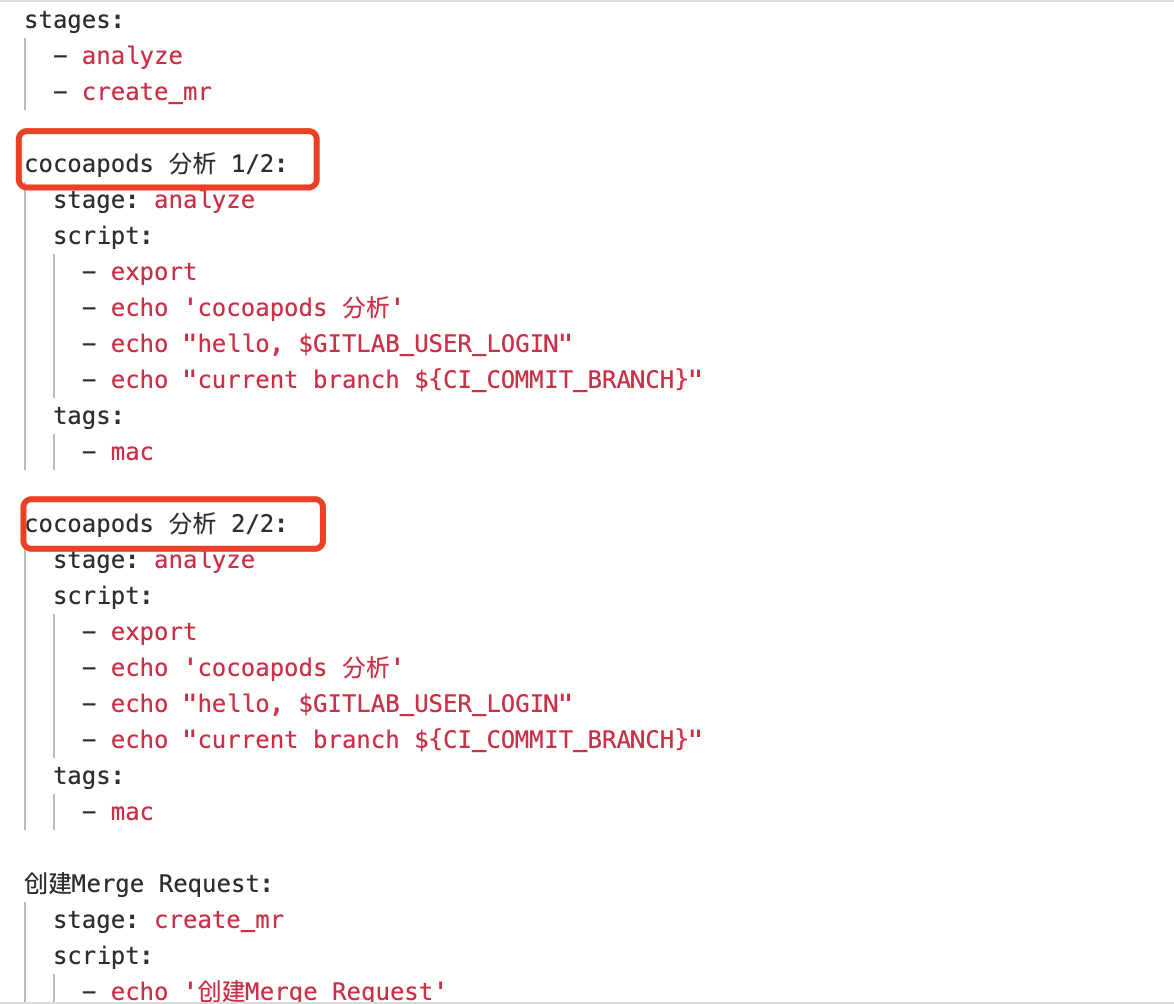
通常拥有多个同一stage下类似任务很多的情况下,会造成流水线图很长很难阅读,为了解决这种问题gitlab CI 支持了分组的功能。
如果你在一个流水线图下的某个job没发现取消/重试按钮,说明这是个组job,也就说它合并了多个Job的组,点击即可展开,如下:
要创建一组作业,可以在gitlab-ci.yml文件中用数字或者以下之一分隔符:
- 斜线(
/),例如slash-test 1/3、slash-test 2/3、slash-test 3/3。 - 冒号 (
:),例如colon-test 1:3、colon-test 2:3、colon-test 3:3。 - 一个空格,例如
space-test 0 3、space-test 1 3、space-test 2 3。
如:
隐藏作业
如果我们想暂时禁掉而不是删除掉作业,我们可以采用以下两种方式进行隐藏作业:
-
注释作业
# hidden_job: # script: # - run test -
以 点(.)开头的作业名
.hidden_job: script: - run test
控制默认关键字和全局变量的继承
-
如下例子:
default: image: 'ruby:2.4' before_script: - echo Hello World variables: DOMAIN: example.com WEBHOOK_URL: https://my-webhook.example.com # 不继承default 以及全局变量 rubocop: inherit: default: false variables: false script: bundle exec rubocop # 继承default的image以及全局变量WEBHOOK_URL rspec: inherit: default: [image] variables: [WEBHOOK_URL] script: bundle exec rspec # 默认继承default 的image以及before_script, 不继承全局变量 capybara: inherit: variables: false script: bundle exec capybara # 显示继承default 的image以及before_script, 继承全局变量DOMAIN karma: inherit: default: true variables: [DOMAIN] script: karma
运行手动作业时指定变量
对于需要手动触发的作业,我们可以指定当次执行的变量,这对于我们想要根据不同的变量进行不同的操作的手动任务很有用:

八、缓存和产物
gitlabCI/CD缓存定义
缓存是作业下载和保存的一个或多个文件。如果使用相同缓存的后续作业将不需要再次下载文件,可增加作业执行的速度。
缓存的关键字用法可查看cache
产物
产物是由作业生成的,如果一个job生成了产物,后续作业可以使用这个产物。
默认情况下产物的有效期是30天,也可以设置产物的过期时间。
产物的关键字可查看artifacts
九、总结
整个gitlab CI/CD 内容可以使用一张图来总结:
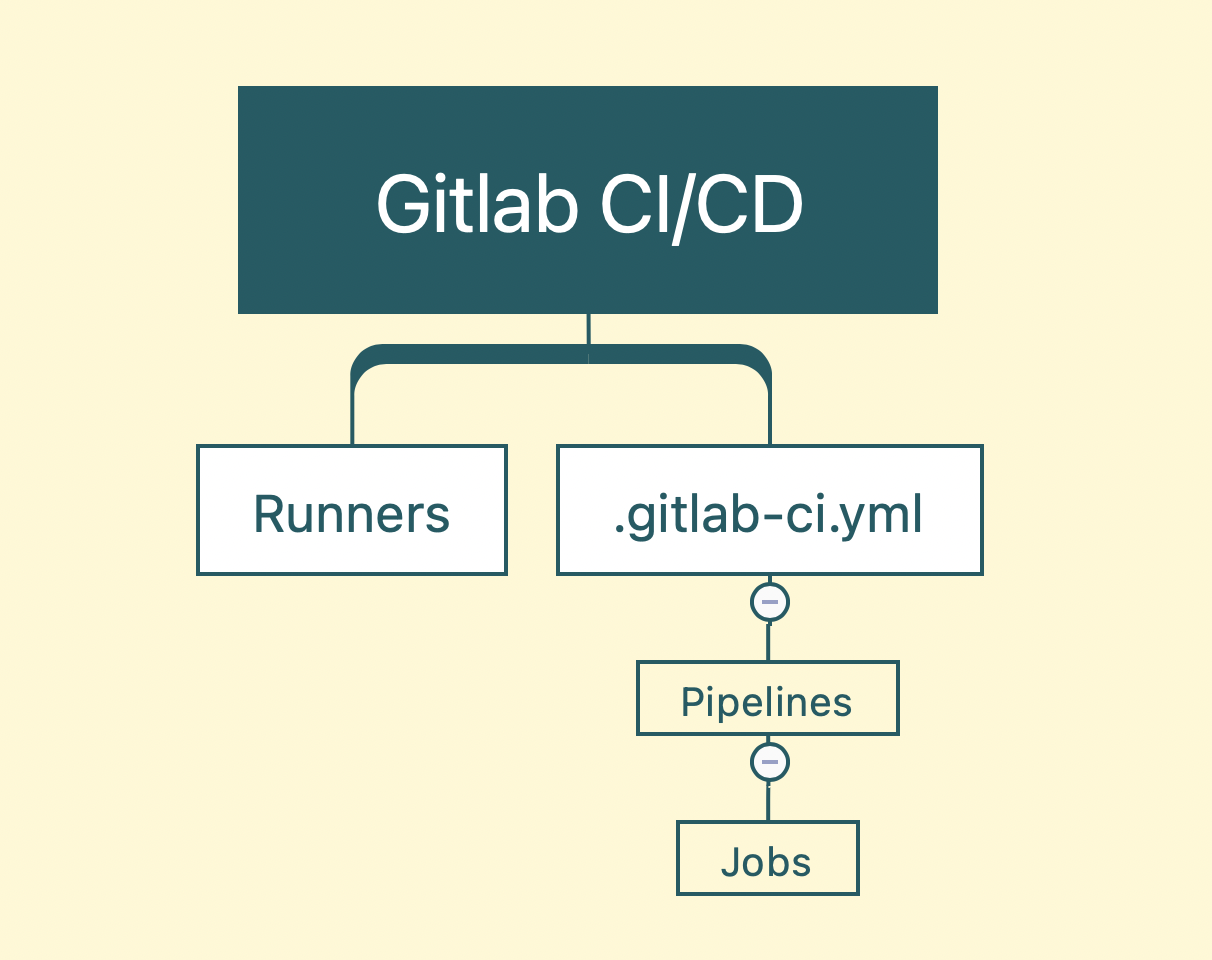
重点是我们1. 搭建runner 2. 构建.gitlab-ci.yml文件以及执行脚本。